![[plotly 맨땅에 헤딩] 3. Plotly를 활용한 미국 주식 Dashboard 만들기 ( yfinance df 전처리 )](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FDaRrh%2FbtrKp6B1dDL%2FAAAAAAAAAAAAAAAAAAAAAFPRVytRBo5Q8SbiHuLl2Z4ZJMZhuap19hsK0LaErQ7b%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DBSty21KwFUe%252FLfozorQVK0dHU2Q%253D)
안녕하세요
전공 개발자가 아니기 때문에 많이 부족합니다. 용어나 단어가 틀린경우가 있을 수도 있습니다.
저도 함께 공부해가기 위해 작성하는 내용으로 틀리거나 보충했으면 좋겠다하는 내용이 있으시면 지체 없이 말씀해주시면 반영할 수 있도록 하겠습니다.
방문해주셔서 감사합니다.
Plotly
Plotly's
plotly.com
해당 내용은 위 사이트 및 기타 블로그들을 참고하여 작성하고 있습니다.
https://minibottle.tistory.com/186
[plotly 맨땅에 헤딩] 2. Plotly를 활용한 미국 주식 Dashboard 만들기 ( yfinance api를 통한 data download )
안녕하세요 전공 개발자가 아니기 때문에 많이 부족합니다. 용어나 단어가 틀린경우가 있을 수도 있습니다. 저도 함께 공부해가기 위해 작성하는 내용으로 틀리거나 보충했으면 좋겠다하는 내
minibottle.tistory.com
이전 글에서는 yfinance를 통해서 DataFrame을 다운받는 것까지 진행했는데요 이번에는 다운받은 dataframe을 시각화를 위해 적절하게 가공 하는 내용을 다루어보려고 합니다.
데이터프레임을 용도에 따라 가공하는 방법은 사용자에 따라서 정말 많은 방법이 있기 때문에, 각자 익숙한 방식을 사용하는게 제일 좋다고 생각합니다.
사용한 함수 목록
1. Unstack : 컬럼이 2중 구조로 되어 있기 때문에 이를 풀어주기 위해서 사용
2. rename : unstack하면서 자동으로 지정된 컬럼명 변경
3. pivot_table : unstack을 통해 풀어준 df를 다시 pivoting
4. Reset_index : df 가공하면서 바뀐 index 재지정
5. sort_values : 원하는 열을 기준으로 df 정렬
6. drop_duplicates : 중복값 제거 [ Ticker , Date기준으로 제거 ]
-> 아마 더 간단하게 한번에 하는 방법이 있을것 같은데.. 아시는 분은 댓글달아주시면 감사드리겠습니다.
1. DataFrame 구조 변환


이전의 Yfinance를 통해 불러들인 DataFrame은 컬럼이 두개의 level로 구성된 multi level column 형태로 구성되어 있습니다.
이런 경우에 나중에 필요에 따라 사용하기에 익숙하지 않기 때문에 이를 풀어 종목을 기준으로 Pivoting된 df 형태로 변환 해주도록 하겠습니다.
- 제가 익숙한 DataFrame 형태
| index | item | column_1 | column_2 | column_3 |
| 1 | a | 0.141213 | 0.730125 | 0.408468 |
| 2 | a | 0.394845 | 0.613302 | 0.906582 |
| 3 | a | 0.601464 | 0.210324 | 0.971002 |
| 4 | b | 0.841292 | 0.102378 | 0.592314 |
| 5 | b | 0.352262 | 0.151774 | 0.607401 |
| 6 | c | 0.869642 | 0.407865 | 0.374746 |
| 7 | c | 0.128661 | 0.460372 | 0.715469 |
기존 df를 위와 같은 형태로 변경해주기 위한 code
df_test = df
df_test = pd.DataFrame(df.unstack()).reset_index() #unstack을 통해 multi columns 풀어주기
df_test.rename(columns={'level_0':'item',0:'value','level_1':'Ticker'},inplace=True) #자동 지정된 컬럼명 변경
df_test_re = pd.pivot_table(df_test,index=[df_test.Date,df_test.Ticker] ,columns='item',values='value') # Pivot_table 구성
df_test_re.sort_values(by=['Ticker','Date'],inplace=True)
df_test_re.drop_duplicates(subset=['Ticker','Date'],inplace = True)
df_test_re.reset_index(inplace=True)
df_test_re저는 Ticker와 Date를 기준으로 정렬해서 사용했습니다.

2. DataFrame 중복값, 결측치 체크
이제 DataFrame을 제가 익숙한 형태로 변환 했으니 DataFrame이 멀쩡한지 ( 중복값, 결측치, 너무 적은 data ..등 )을 확인하고 다음으로 넘어가도록 하겠습니다.
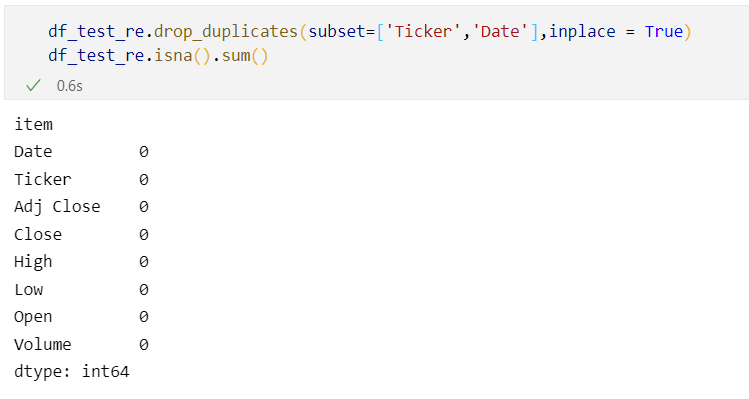
drop_duplicetes의 경우 중복값을 제거해 주는 함수입니다. 기준이 되는 column을 지정해주면 되는데 저는 같은 Ticker에 같은 Date를 가진 값이 있으면 이를 중복이라고 판단하고 제거하도록 하였습니다.
pd.pivot_table(df_test_re, index = ['Ticker'], values = 'Date', aggfunc = 'count')
각 Item 별로 동일한 수의 Date값이 잘 존재하는것까지 확인했습니다.
네 이제 DataFrame에 대한 변환 및 결측치 확인까지 완료했으니, 이제 Dashboard를 구상하고, 이를 위해 필요한 Graph종류 결정 및 구현만 하면 될 것 같습니다.
함께해주셔서 감사합니다.